テキストファイルなどの内容を1行ずつ取得し、必要な部分だけ取り出す方法を紹介します。
今回の手順としては以下になります。
1.テキストを読み込む(テキストでなくても可)(Read Text File)
2.テキストを1行ずつに分割する(assign)
3.分割したテキストを繰り返しで取得する(for each)
4.必要なもだけ取得する(if)
テキストでもPDFでもなにかをクリップボードにいれたものでもなんでもいいのですが、
改行があるテキストを読み込みます。
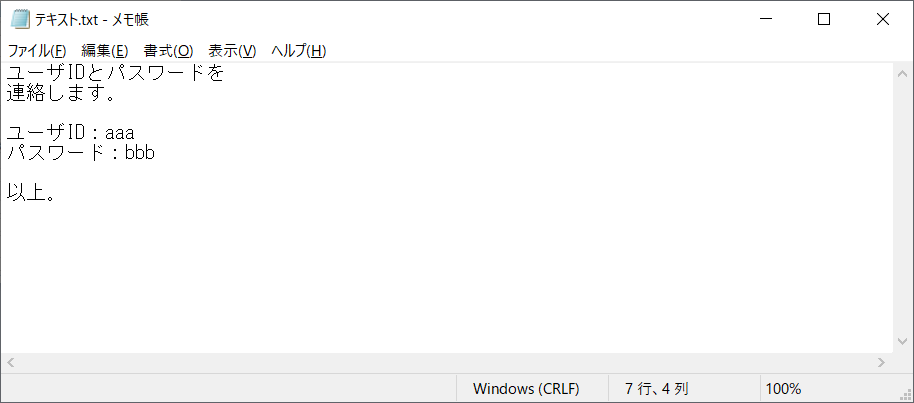
今回はサンプルとして以下のようなテキストを読み込みます。
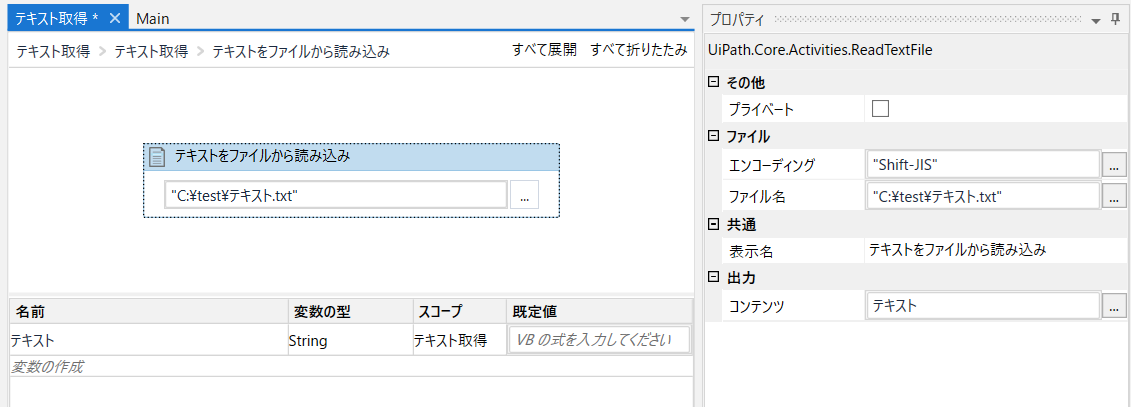
テキストファイルの読み込みであれば、Read Text Fileを使います。
取得したテキストをString型の配列に改行を区切り文字として設定したSplitで入れます。
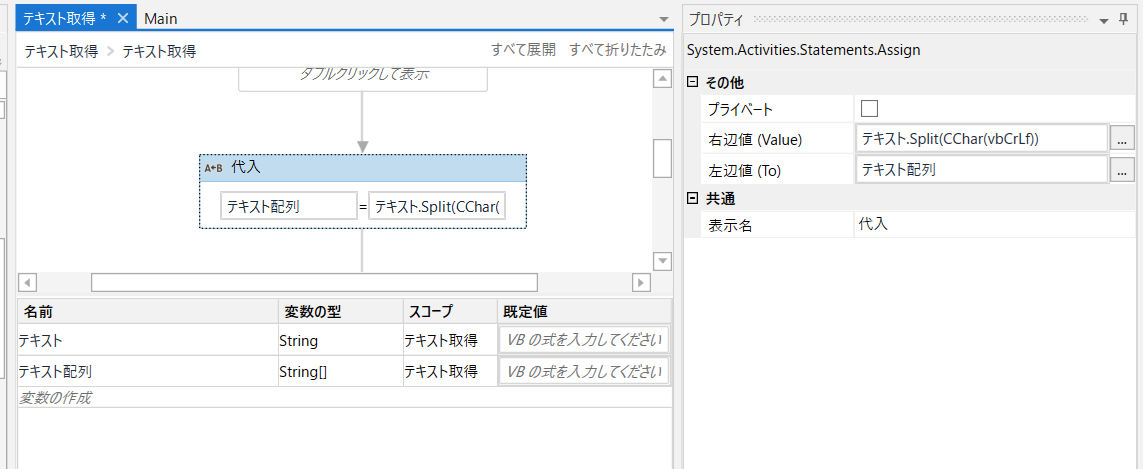
代入(assign)で以下のように設定します。
テキスト配列(String[]) = テキスト.Split(CChar(vbCrLf))
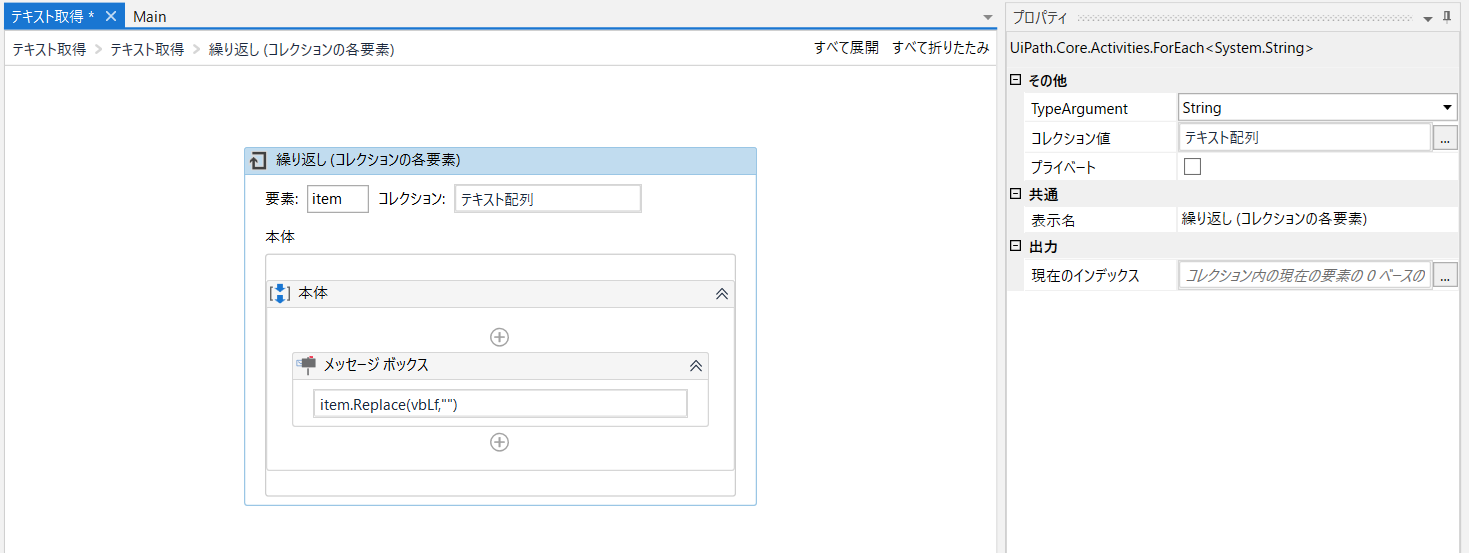
配列に入れた文字を繰り返しで取得していきます。
コレクションにテキスト配列を指定し、TypeArgumentはStringとします。
以下の例ではメッセージボックスでどのような値が取得できるか見ています。
値を取得する際には、余分な改行が残ってしまっているのでReplaceしています。
ちなみにこれを実行すると以下のようなメッセージボックスが出てきます。
1行ずつ取得できているのがわかりますね。
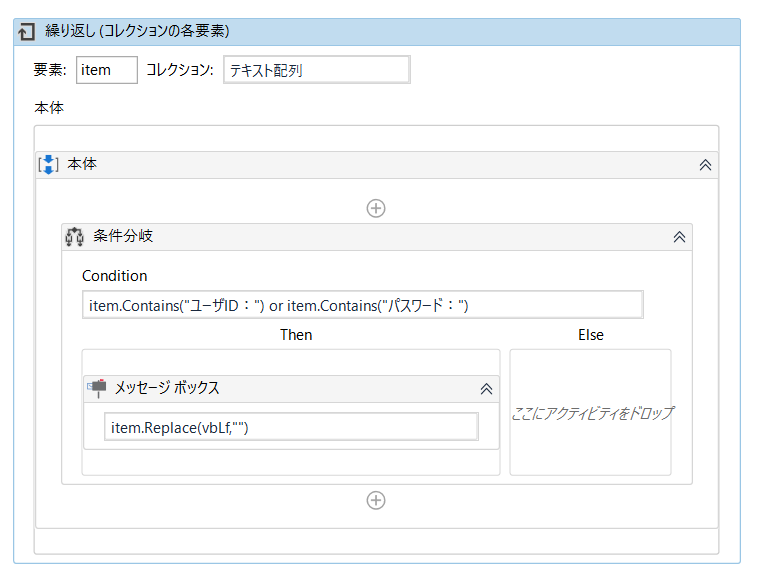
ifを使って必要な行だけ取得します。
今回の場合はユーザIDとパスワードが記載されている行だけ取得したいと思います。
条件式には以下のように設定します。
item.Contains(“ユーザID:”) or item.Contains(“パスワード:”)
これでitemに「ユーザID:」または「パスワード:」が含まれている場合のみ、Thenの方にいきます。
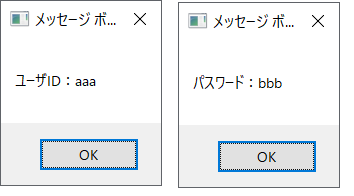
これを実行すると以下のようなメッセージボックスが出てきます。
さっきと比べてメッセージボックスの数が減りましたね。
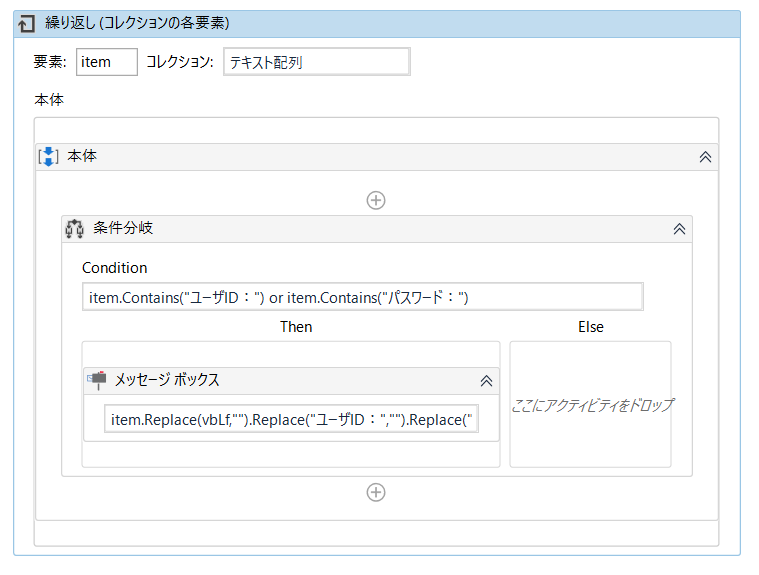
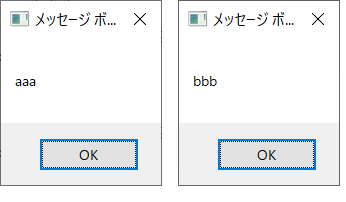
もし、「ユーザID:」とかもいらないという場合は、Replaceで処理できます。
item.Replace(vbLf,””).Replace(“ユーザID:”,””).Replace(“パスワード:”,””)
以上、テキストファイルなどの内容を1行ずつ取得し、必要な部分だけ取り出す方法でした。
最後はメッセージボックスで出力しましたが、抜き出したものをテキストやExcelに張り付けたりもできますので
応用して試してみてください。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}