【UiPath】PDFの文字を読み込む方法(文字が画像として保存されている場合)(OCR)
PDFの文字を読み込む方法(文字が画像として保存されている場合)について紹介します。
今回はOCRを使います。もし文字がテキストとして保存されている場合はこちらをご参照ください。
まず、準備として、以下のPDFを用意しました。
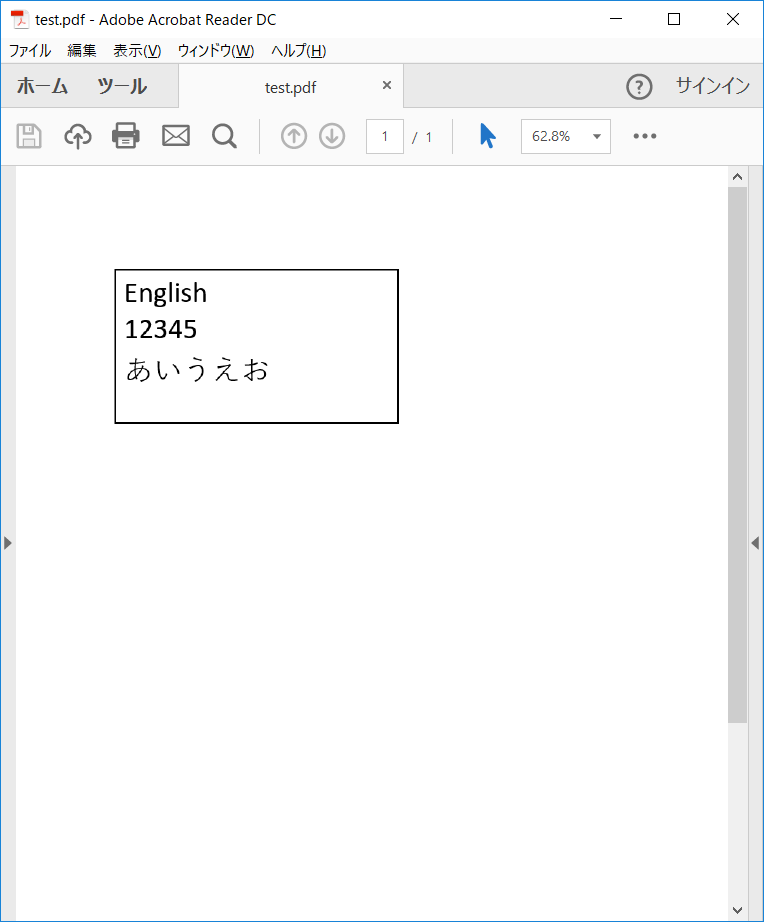
PDF内の文字は画像になっています。(コピペしても文字を読み取れない状態)
ではUiPathで、上のDESIGNタブのScreenScrapingをクリックします。

すると、対象を選択するモード(Indicate on Screenを押したようなモード)になるので、PDFの画像部分を選択します。
以下のような画面が表示されます。
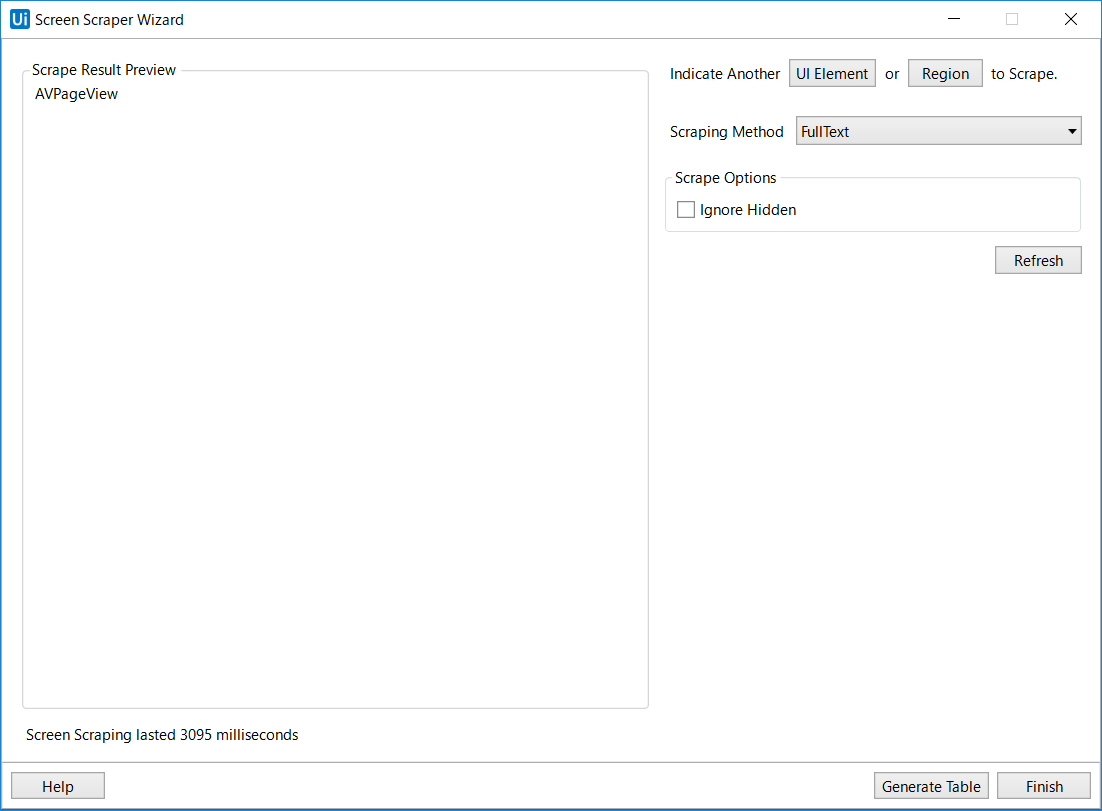
ここで、いくつか設定を変えていきます。
まず、Scraping MethodをOCRに変更します。
次にOCR Engineをお好みのエンジンに変えます。(デフォルトではGoogleですが、ここでは日本語が使えたのでMicrosoftにします。)
Languageもお好みのものにします。(日本語がない場合については後ほど記載します)
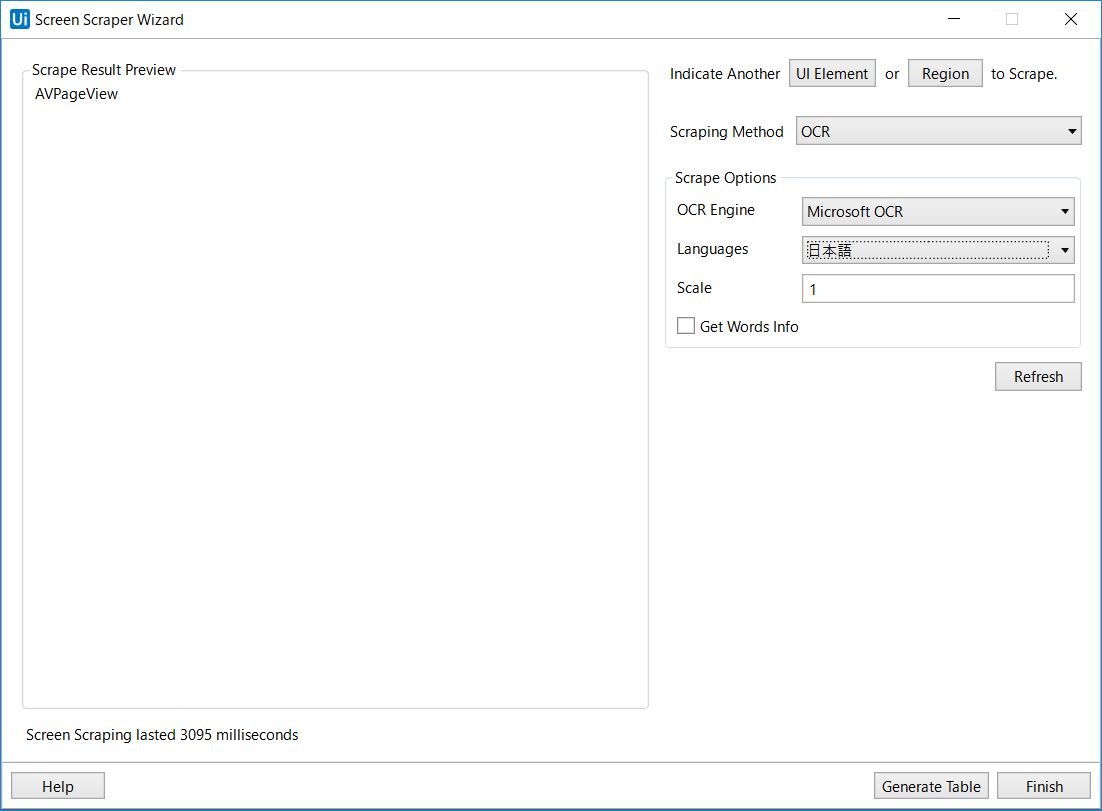
ここまでいれたら、Refreshボタンを押します。
そうすると、以下のようにScrape Result Previewの部分が変わるかと思います。
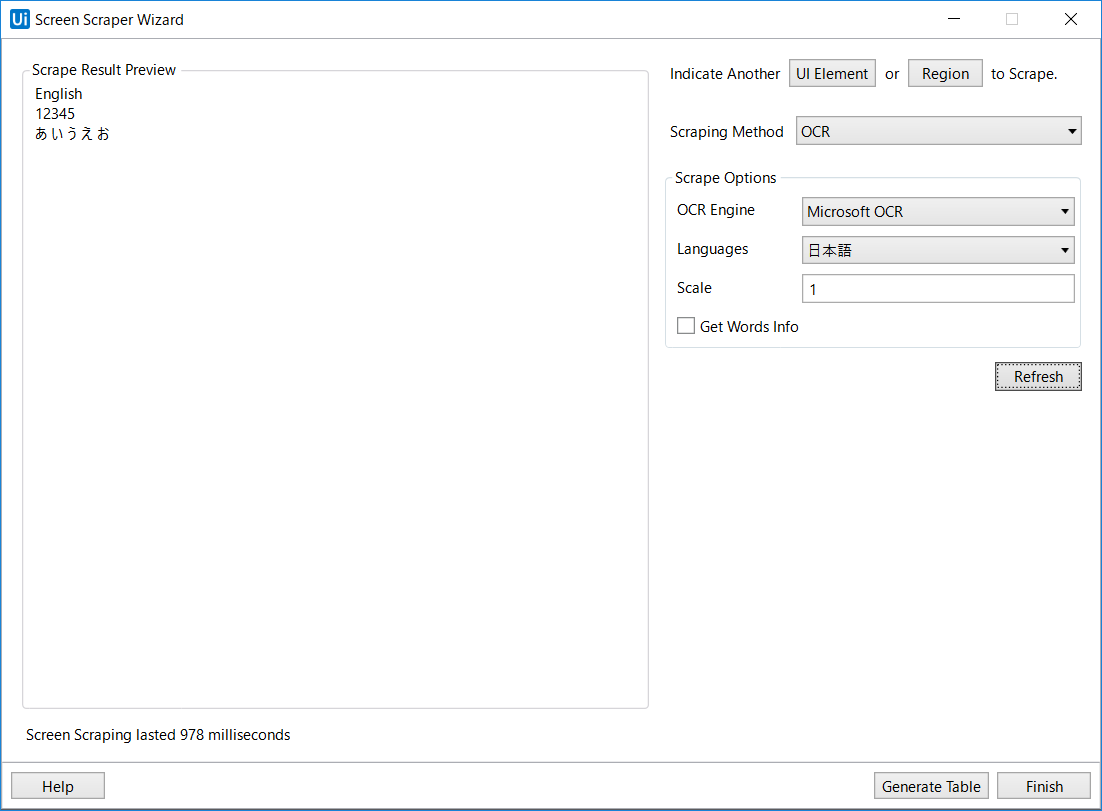
これできれいに文字が出ていたらそのままでよいですが、誤認識していた場合は、Scaleの数字をあげてみると、拡大して認識するため少し認識率が上がるかもしれないです。Scaleの数字をかえたら、またRefreshを押して確認してみましょう。
確認が終わったら、右下のFinishボタンを押します。
すると以下のようなワークフローが自動で作成されます。
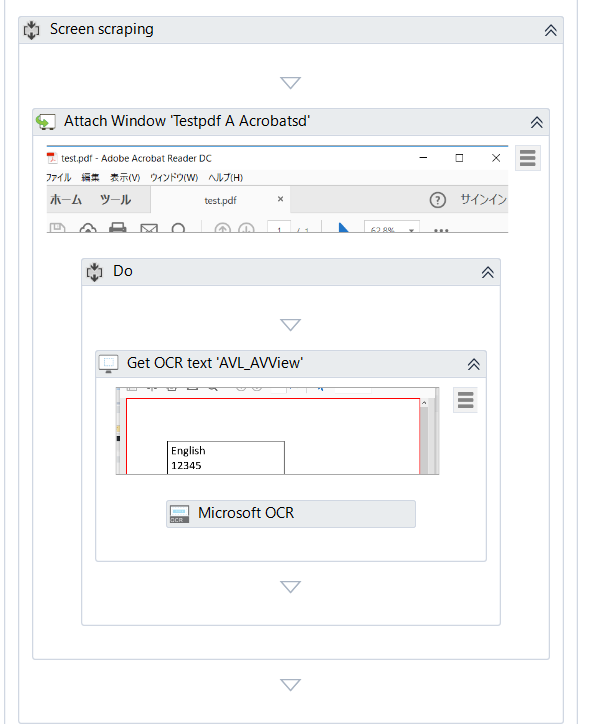
あとは取得したテキストをテキストファイルに出力してみます。
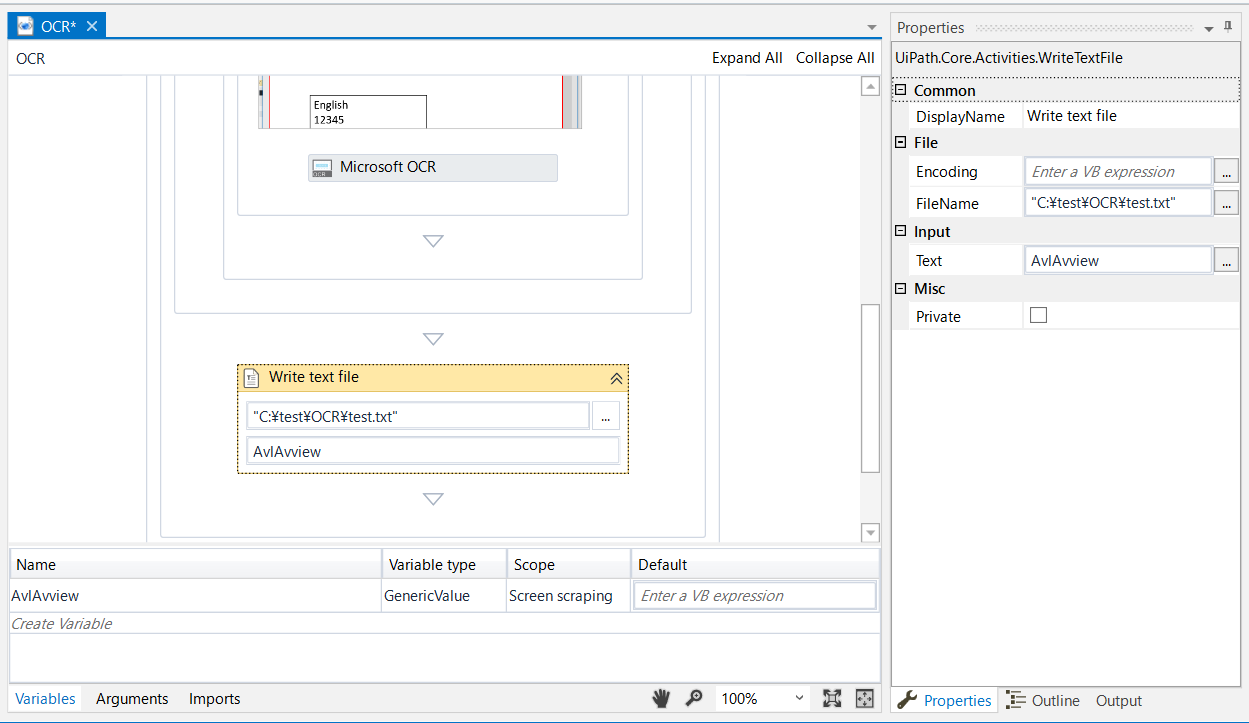
出力にはWrite Text Fileを使います。
なお、Screen Scrapingを使うと、自動的に「AvlAvview」という変数が作成されるため、それをそのまま使います。
ちなみにこの変数はGet OCR TextアクティビティのPropatiesのOutputのTextで設定されています。
これで、実行して出力されたテキストファイルは以下のようになります。
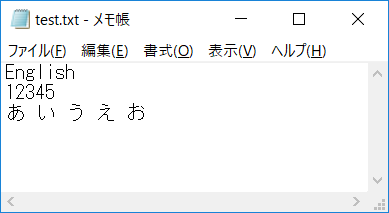
あいうえおの中に変なスペースは入っていますが、とりあえず取れました。
ちなみに今回のサンプルでは、PDFを開いた状態から作成しているため、もしPDFを開くところから使いたいという場合はこちらを参考にし、Open ApplicationかStart Processをいれてから取得するようにしましょう。
※
OCRで日本語が選択出来ない場合は、以下の記事を参考にインストール等をしてみてください。(実際にやってみてはいないので、保証はできませんが…)
OCR / Screen Scrapingで日本語が利用できない。
UiPath内の掲示板の記事です。
以上、PDFの文字を読み込む方法(文字が画像として保存されている場合)でした。
OCRは結構使いたい場面が多いかと思いますが、まだOCRの精度自体は100%とはいかないようなので、使う際は気をつけてください。